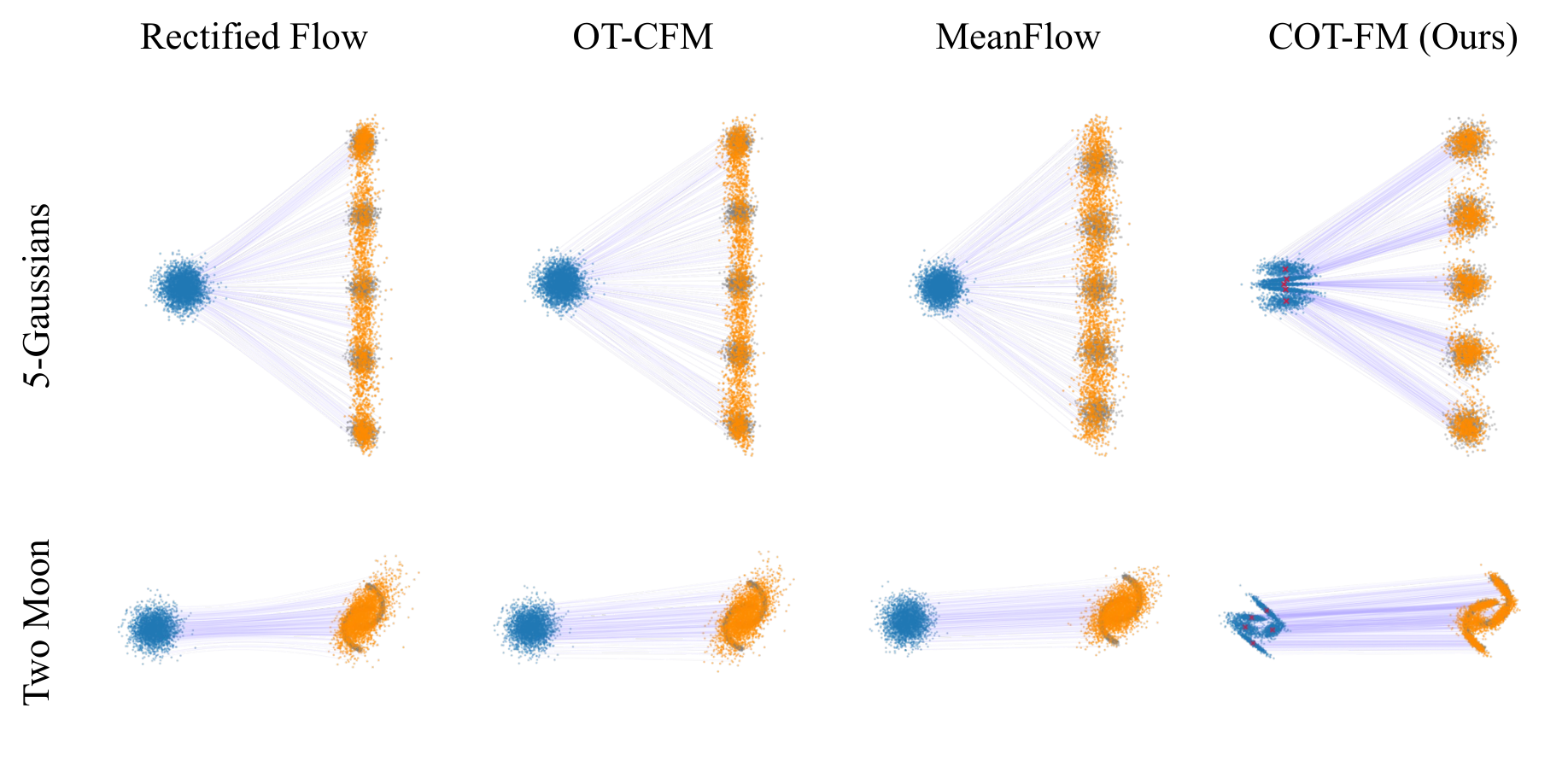
If we partition the data into clusters, then OT within each cluster becomes a much smaller and
more homogeneous subproblem — making batch OT a far better approximation locally.
The key challenge is finding the right source distribution for each cluster.
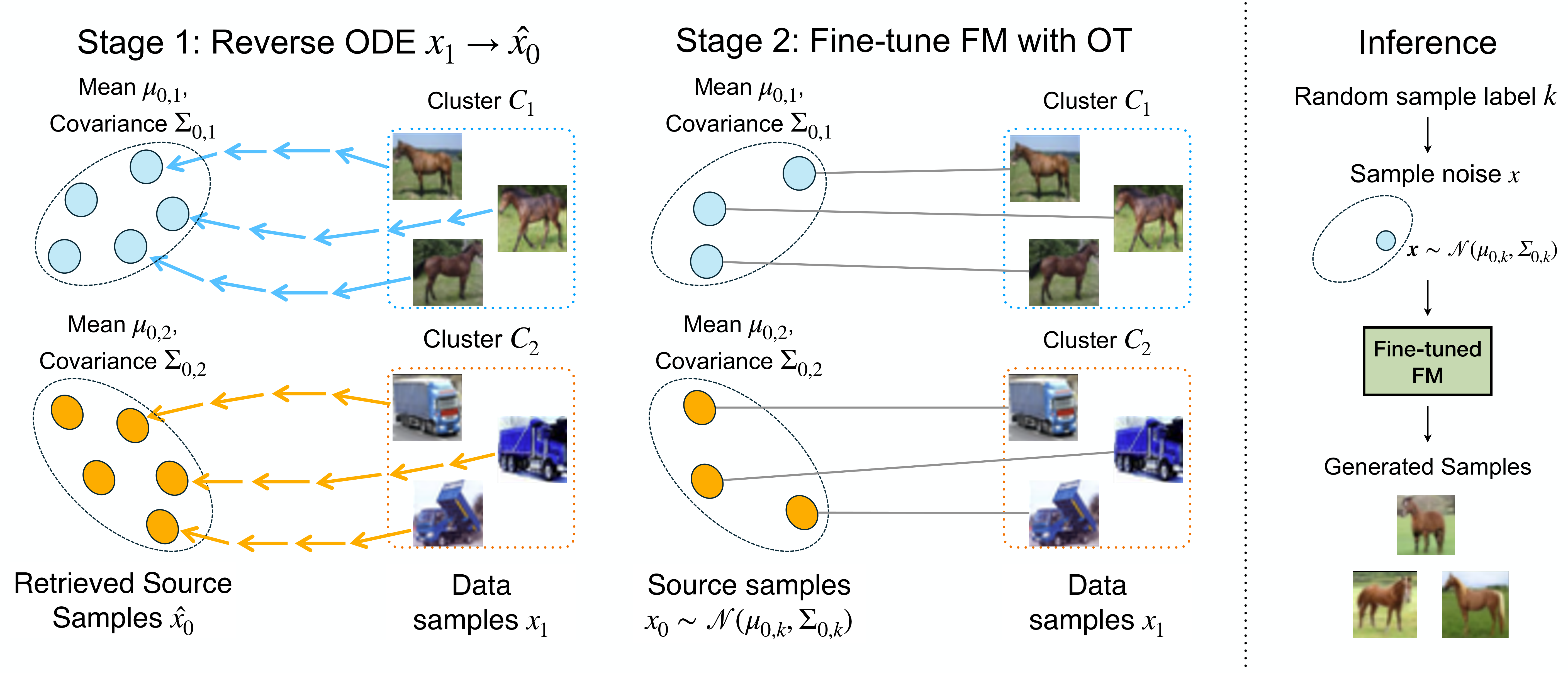
COT-FM solves this by bootstrapping from a pretrained FM model. A pretrained FM
model, even if trained with random coupling, has learned flows that are reversible and
non-intersecting. We exploit this: by integrating the ODE backward, each data sample
\(\mathbf{x}_1\) traces back to its natural source region, giving us the cluster-wise source
distributions for free.
Formally, we reverse ODE integration to retrieve the source sample of data sample
\(\mathbf{x}_1\):
\[
\hat{\mathbf{x}}_0 := \mathbf{x}_1 - \int_0^1 \mathbf{v}_\theta(\hat{\mathbf{x}}_t,\, t)\,\mathrm{d}t
\]
Collecting all reversed source samples for cluster \(\mathcal{C}_k\), we fit:
\[
\boldsymbol{\mu}_{0,k} = \frac{1}{|\hat{X}_{0,k}|}\sum_{\hat{\mathbf{x}}_0}\hat{\mathbf{x}}_0,
\qquad
\boldsymbol{\Sigma}_{0,k} = \frac{1}{|\hat{X}_{0,k}|}\sum_{\hat{\mathbf{x}}_0}
(\hat{\mathbf{x}}_0 - \boldsymbol{\mu}_{0,k})(\hat{\mathbf{x}}_0 - \boldsymbol{\mu}_{0,k})^\top
\]
\[
p_{0,k}(\mathbf{x}) = \mathcal{N}\!\left(\mathbf{x};\;\boldsymbol{\mu}_{0,k},\;\boldsymbol{\Sigma}_{0,k}\right)
\]
Batch OT is then applied within each cluster between \(p_{0,k}\) and
\(\mathcal{C}_k\). Because source and target are now both concentrated in the same region
of space, the batch approximation is far more accurate — yielding significantly straighter flows.
COT-FM alternates between refining source distributions (Stage 1) and fine-tuning the FM model
(Stage 2); empirically, 2 alternation rounds suffice.
Importantly, COT-FM only modulates the target probability path without altering the FM
architecture or input-output mechanisms, making it broadly compatible with existing FM models.