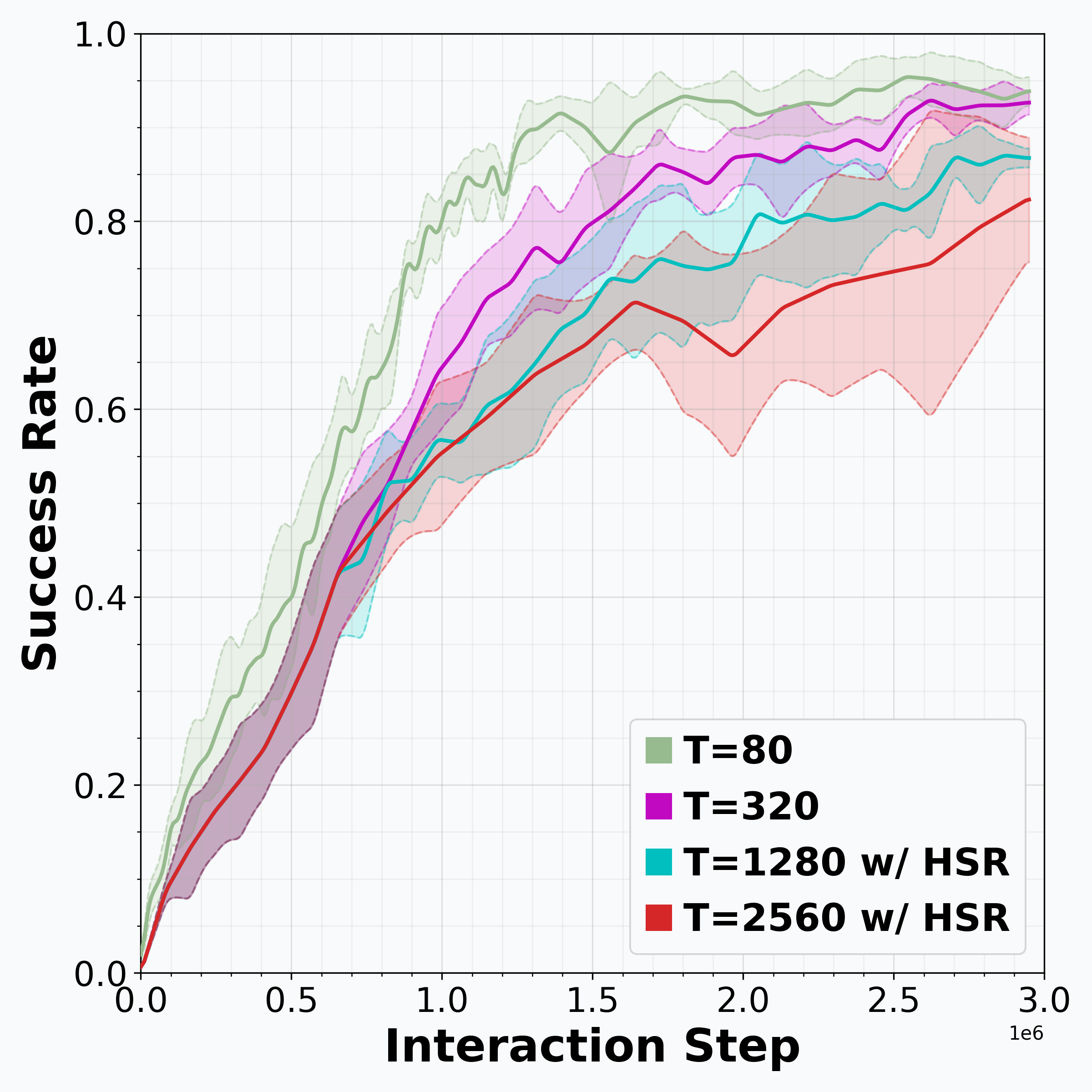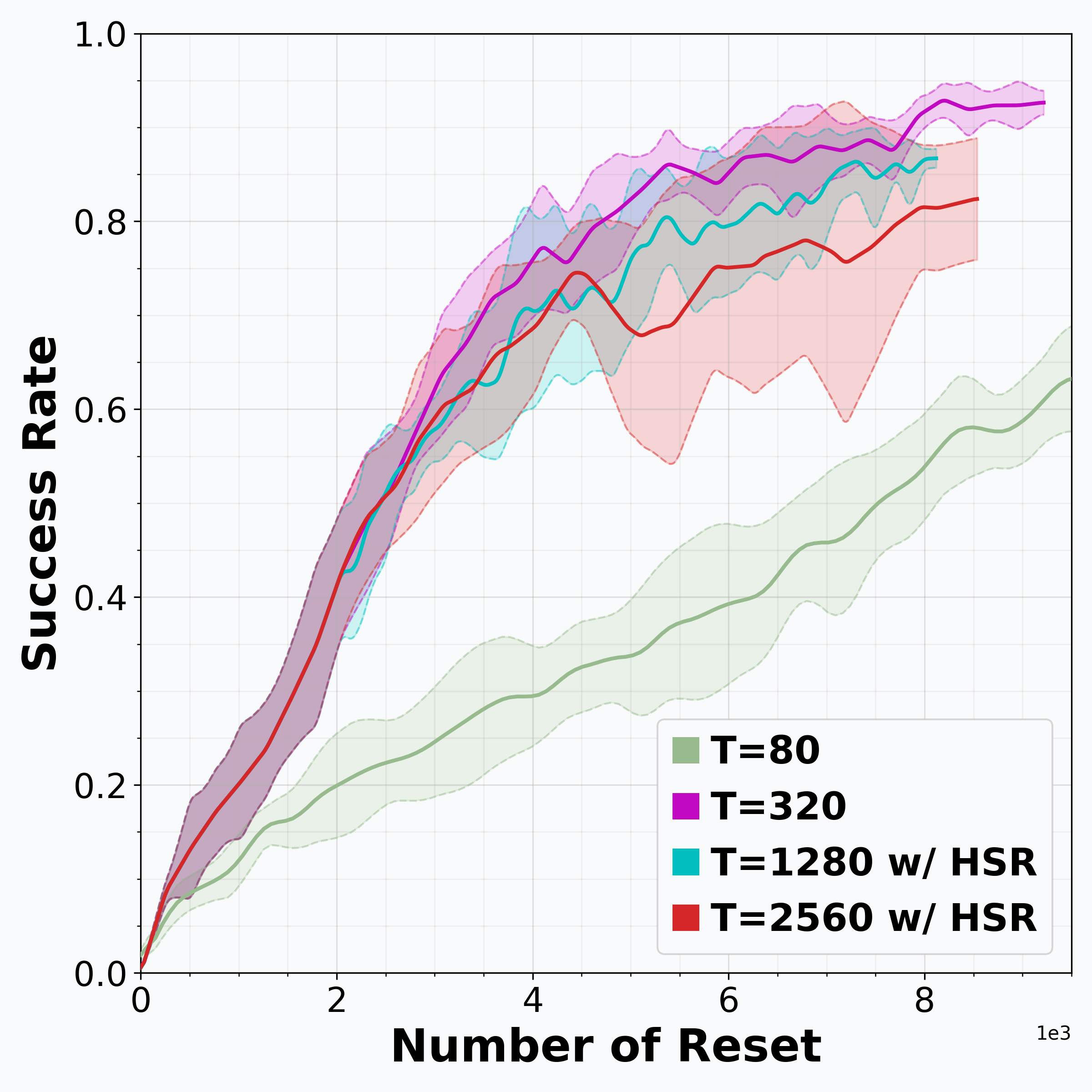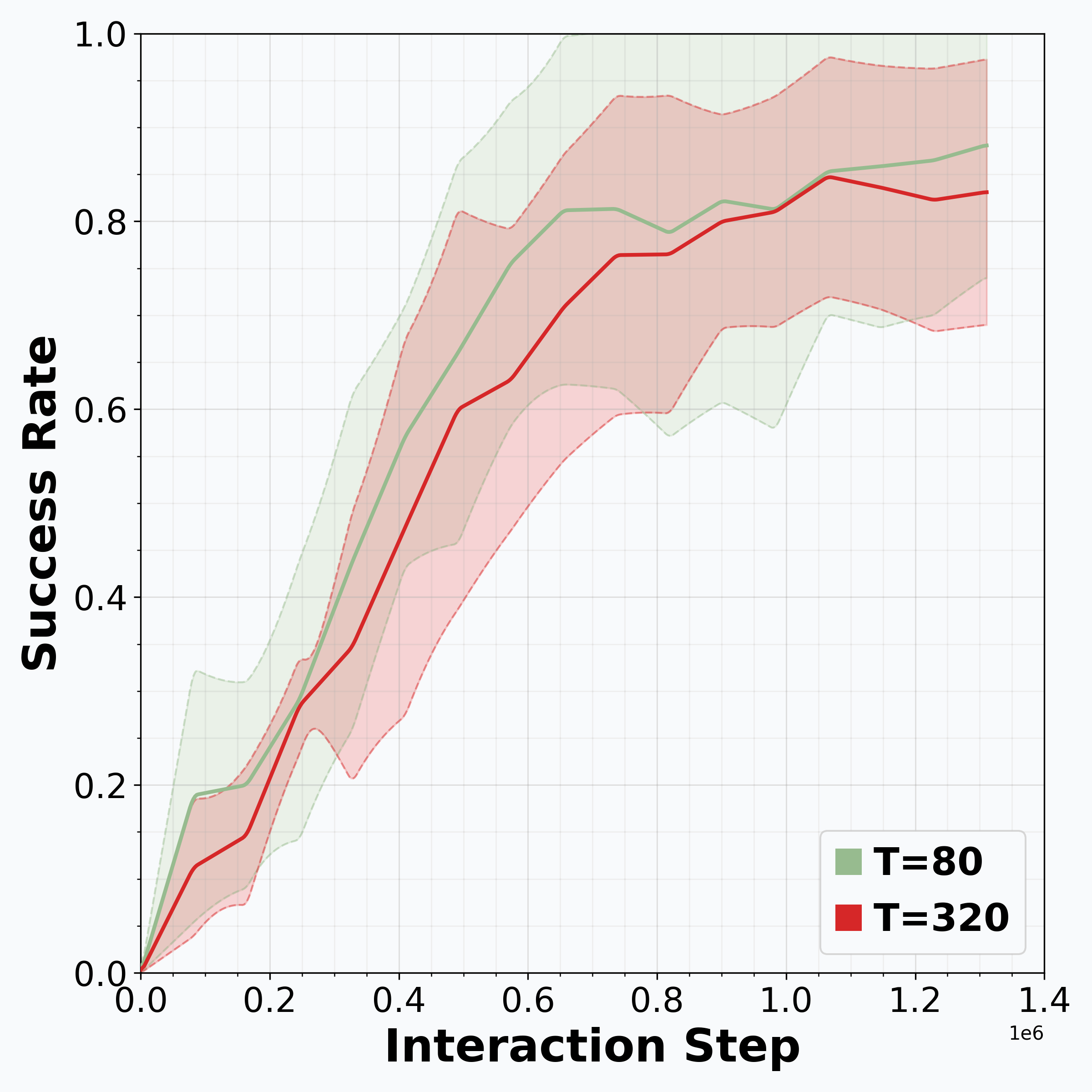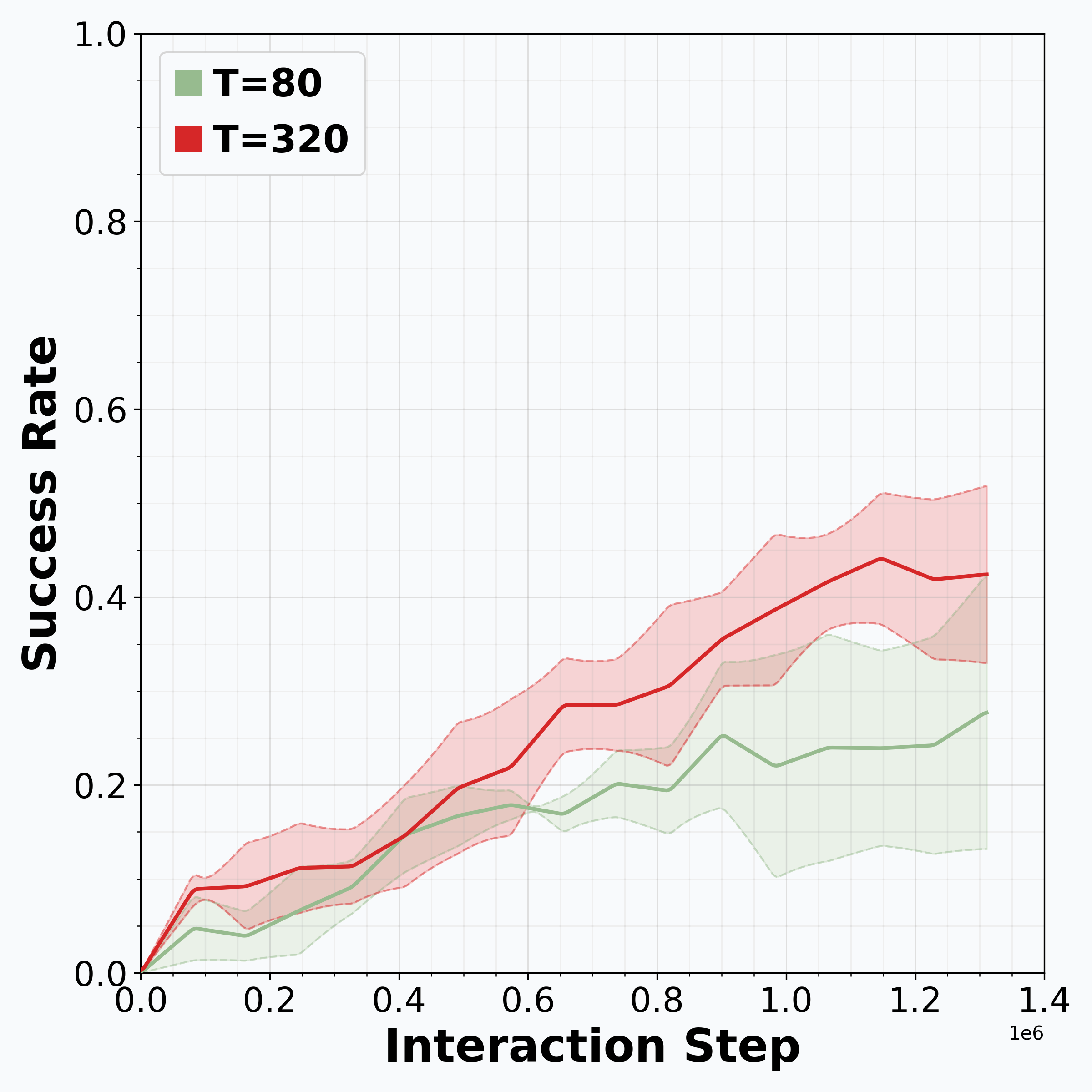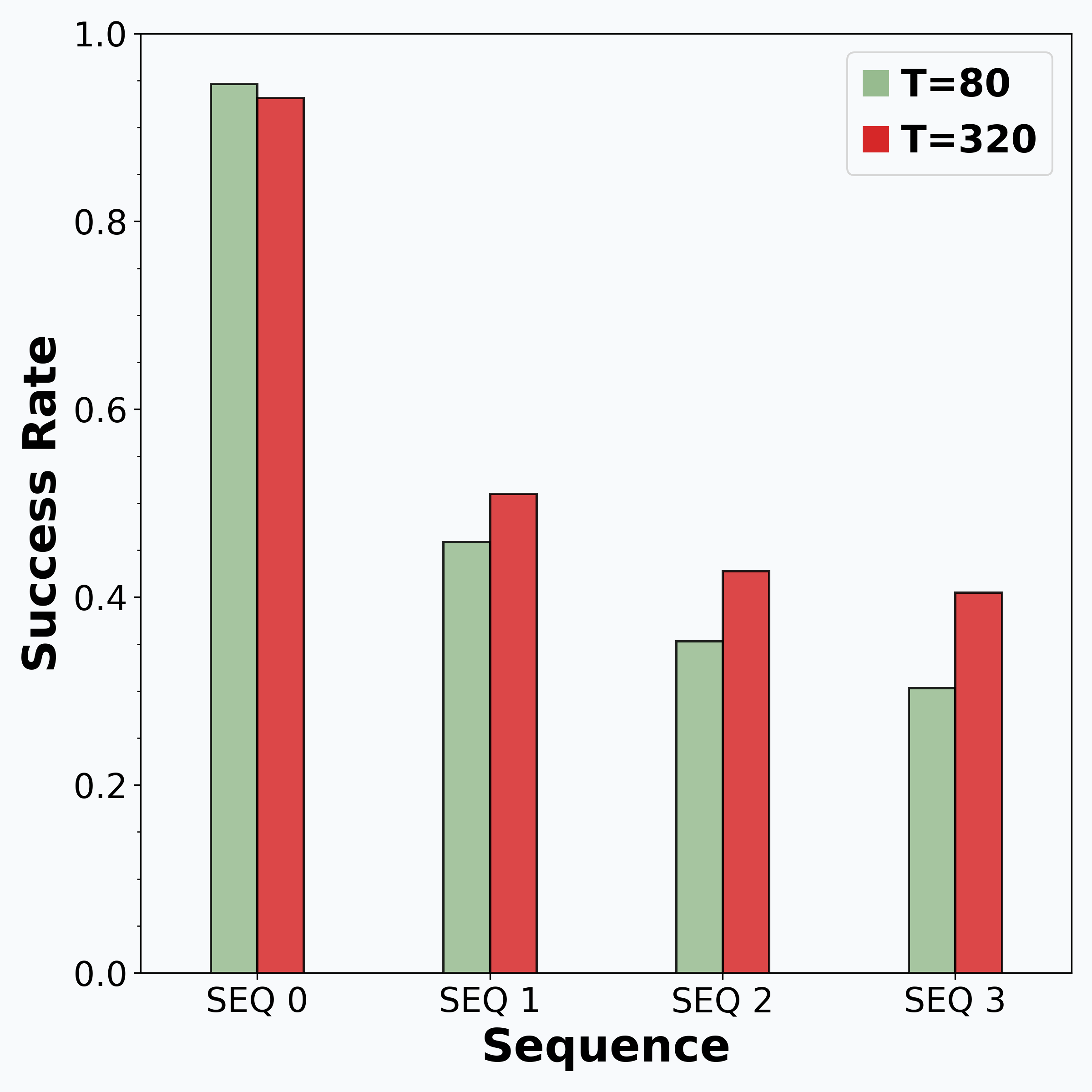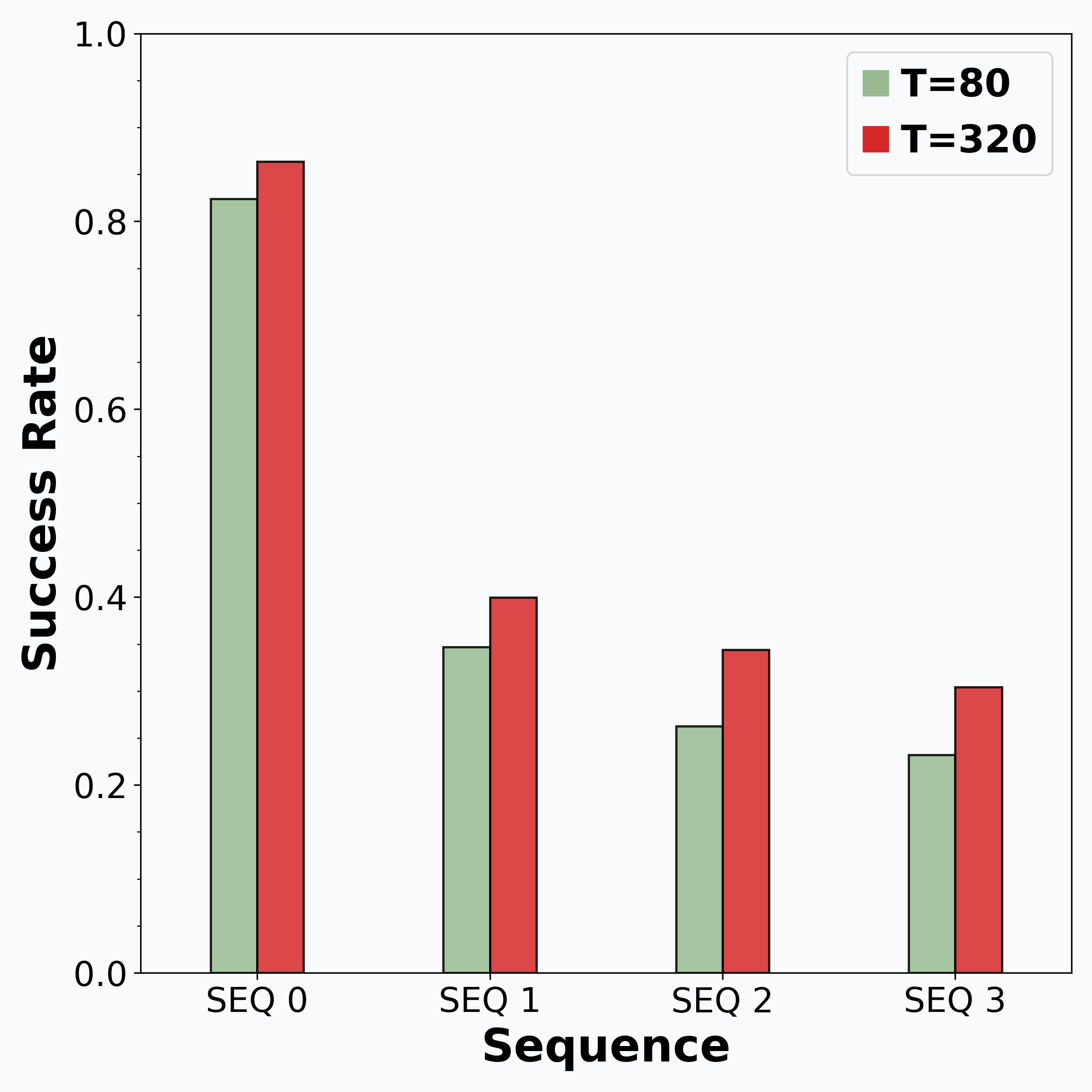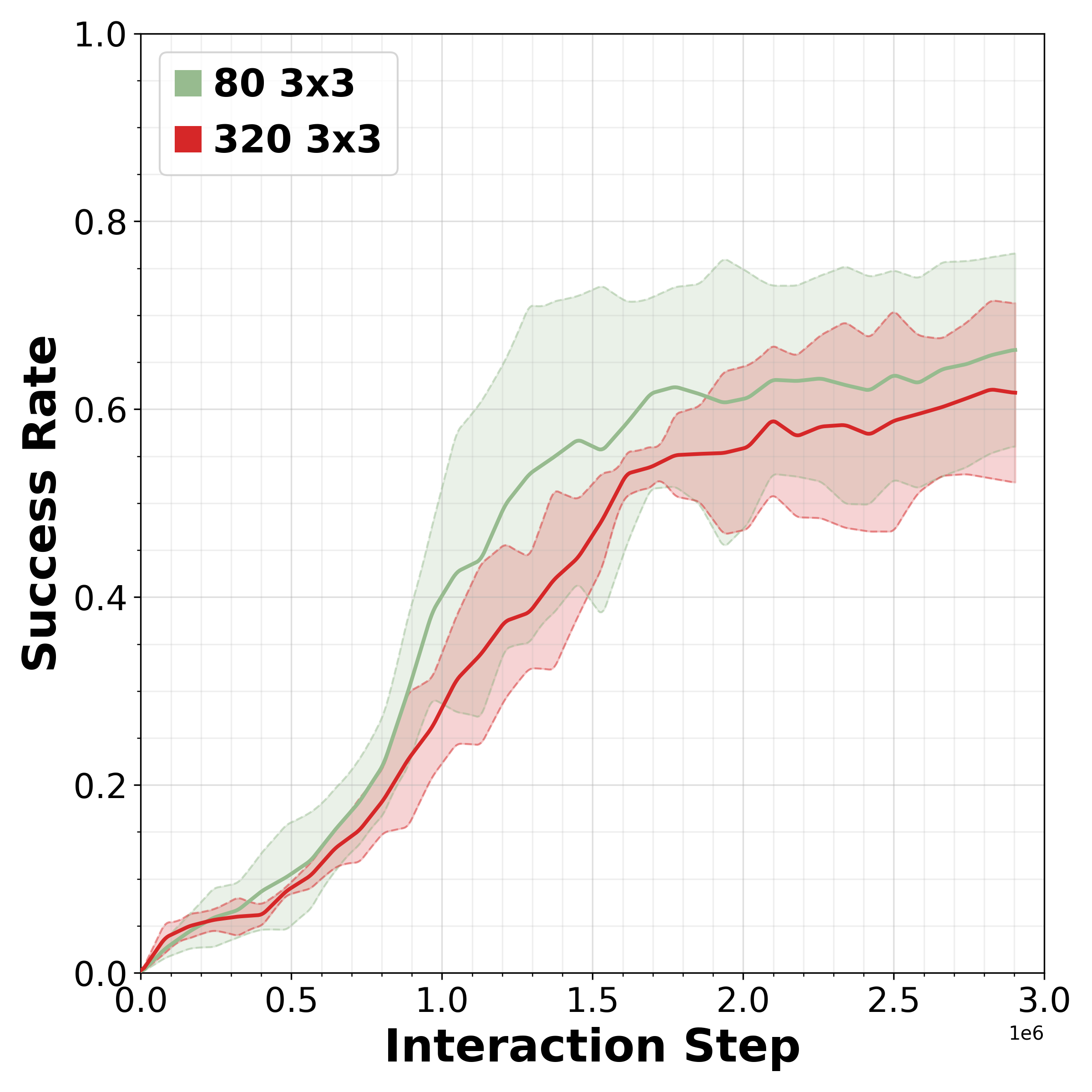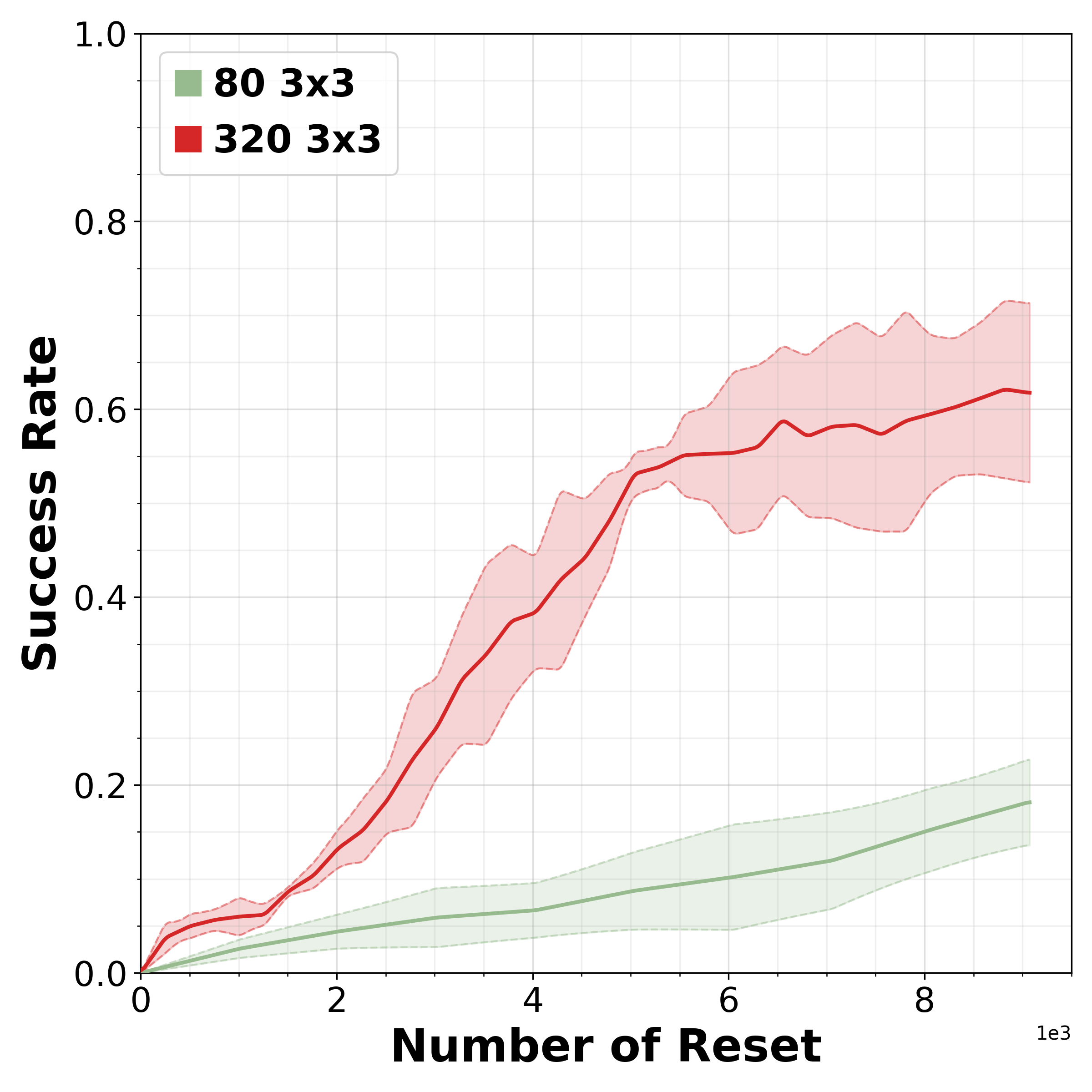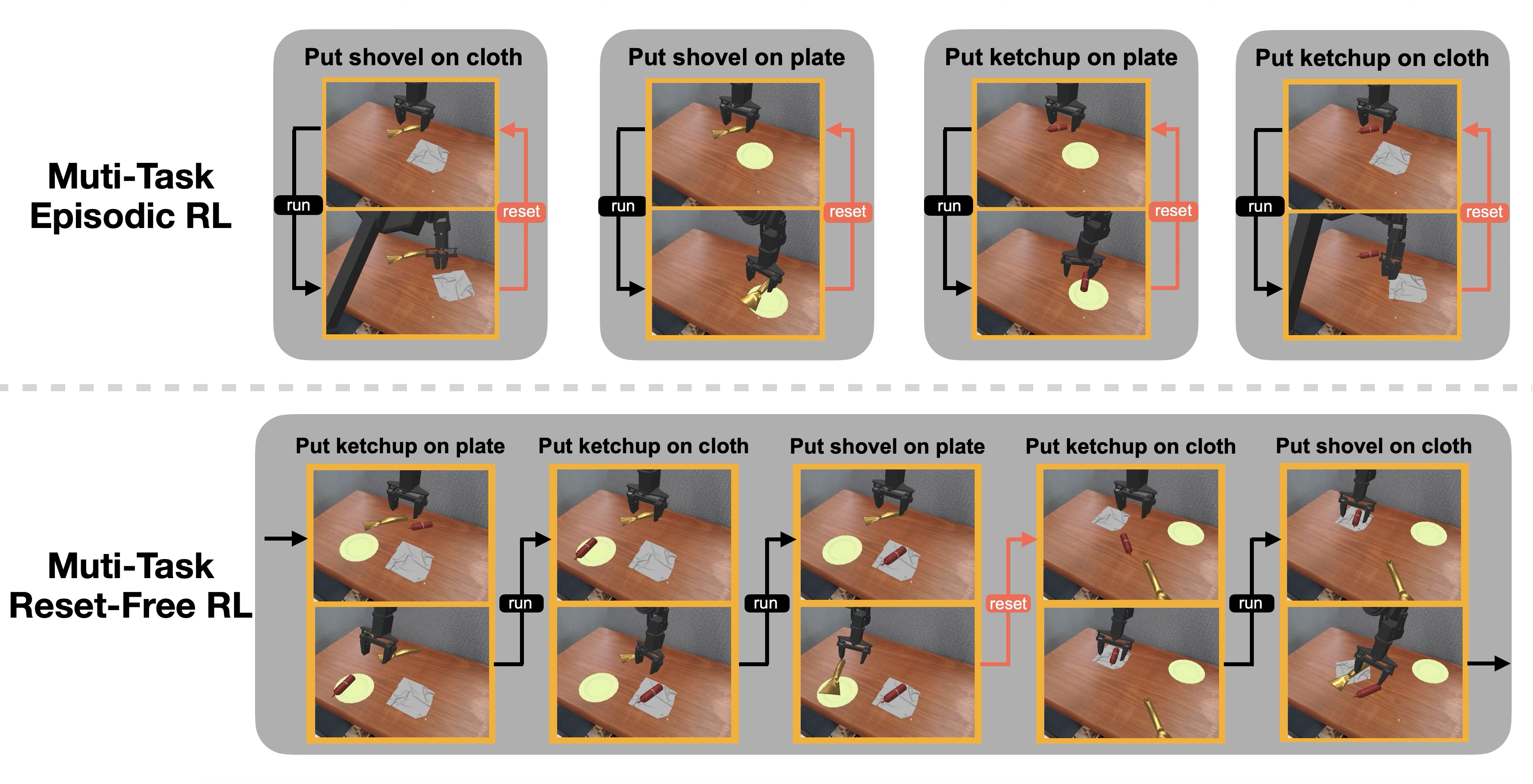
Reinforcement learning (RL) is promising for adapting robot policies to unstructured real-world environments. However, standard RL pipelines rely on episodic training with frequent scene resets, which is impractical for real-world deployment due to the need for substantial human intervention. We introduce CRONOS (Continual Robotic Operations in NOn-episodic Settings), a simulation benchmark for studying reset-free multi-task RL under long-horizon interactions and constrained reset budgets.
To reflect realistic deployment, CRONOS leverages high-fidelity physics simulators, adopts shared-scene multi-task settings, targets the adaptation of state-of-the-art robot policies, and formalizes reset-free learning under a fixed reset budget. We show that naively fine-tuning pre-trained policies fails in reset-free settings; however, these challenges can be mitigated through intelligent reset allocation and by addressing biases in pre-trained models. Finally, we demonstrate that reset-free training enhances long-horizon manipulation and improves generalization to Held-out Configuration object configurations and task sequences.